Многопоточность. Потоки / threads.
Одной из ключевых особенностей в современных языках программирования – является использование многопоточного режима выполнения программы, отчасти это стало возможным благодаря технологии “Hyper-Threading” от компании Intel, появлению многоядерных и многооточных вычислительных систем и в целом больших возможностей у современных вычислителей, когда ядро процессора какое-то время «не занято»
Что из себя представляет многопоточность?
Классический код – это набор последовательных инструкций / операций выполняющихся ядром вычислителя, но при возможности нескольких потоков (считаем что нескольких физических или виртуальных вычислителей) мы можем выполнять инструкции из разных функций «вперемешку».
Довольно подробно принцип работы многопоточности на примере ОСРВ FREERTOS расписан на странице https://it-ouroboros.com/freertos/vvedenie-v-freertos/
Основные моменты:· Планировщик запоминает текущий код (функцию и апраметры) у задачи и при следующем вызове задачи «продолжает» код.· Работа с задачами в потоках идет в временные кванты (отрезки времени), которые не привязаны к «длительности» задачи, т.е. задача дробится на N квантов.· Задачи могут выполняться как на 1физическом ядре/потоке так и на различных, в данном случае это не принципиально (влияет лишь на производительность)
В крупных/мощных вычислителях принцип остался тот же, разве что при наличии нескольких ядер или ресурсов задачи будут более равномерно распределены между ними.
В языке C++ для работы с потоками используются библиотеки:
#include "thread" //потоки
#include "chrono" //задержкиРассмотрим работу потоков на примере 2 функций, назовем их Task1 и Task2
void Task1()
{
cout<<"Task_1 ID="<<this_thread::get_id()<<endl;
for (int var = 0; var < 5; ++var)
{
cout<<"Task #1 is in progress #"<<var<<endl;
this_thread::sleep_for(chrono::milliseconds(100)); //блокирует/переводит текущий поток в режим ожидания на 100мс
}
}
void Task2(string str)
{
cout<<"Task_1 ID="<<this_thread::get_id()<<endl;
for (int var = 0; var < 10; ++var)
{
cout<<" >>Task #2 is in progress. Print "<<str<<" #"<<var<<endl;
this_thread::sleep_for(chrono::milliseconds(200)); //блокирует/переводит текущий поток в режим ожидания на 200мс
}
}Кратко опишем основной функционал:
/*
* this_thread::sleep_for(chrono::milliseconds(200)); //блокирует/переводит текущий поток в режим ожидания на 200мс
* this_thread::get_id(); //получить ID потока
* th_1.detach(); //НЕ ожидать окончания работы th_1, когда последняя задача прекратит работу, th_1 также прекратит работу
* th_2.join(); //ожидать окончания работы th_2, когда main дойет до этого метода, будет ожидание окончания работы th_2
*/
Напишем код в функции main:
int main()
{
Sleep(2000);
cout<<"Main ID="<<this_thread::get_id()<<endl;
thread th_1(Task1); //создаем поток th_1 и передаем указатель на функцию Task1
thread th_2(Task2,"task/thread 2"); //создаем поток th_2, передаем указатель на функцию Task2 и аргумент
th_1.detach(); //НЕ ожидать окончания работы th_1, когда последняя задача прекратит работу, th_1 также прекратит работу
th_2.join(); //ожидать окончания работы th_2, когда main дойет до этого метода, будет ожидание окончания работы th_2
return 0;
}Отдельное внимание стоит уделить функциям thread.detach() и thread.join()
метод detach «говорит» планировщику, что после выполнения остальных задач выполнение этого потока НЕ ТРЕБУЕТСЯ.
Т.е. когда выполнятся все задачи автоматически завершится и выбранная задача.
метод join «говорит» планировщику, что необходимо ОЖИДАТЬ выполнения текущей задачи, т.е. функция main дойдя до этого метода будет висеть в ожидании.
Примечание: хотя мы и говорим «функция main дойдя до этого метода будет висеть в ожидании» на самом деле имеется в виду тот поток, который создал/вызвал наш поток, который мы хотим выполнить.
В примере выше для потока 1 выбран detach и т.к. он явно выполняется меньше потока 2, то в консоль выводятся все ожидаемые сбщ.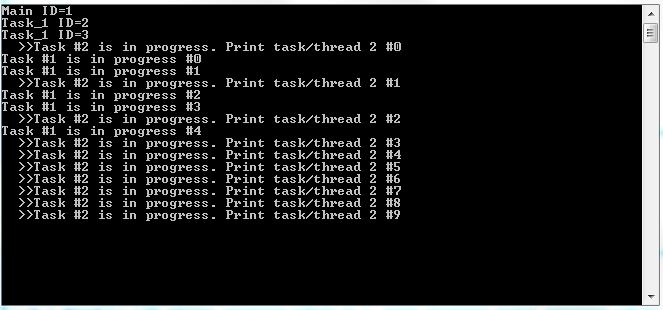
Если бы в потоке 1 мы изменили задержку, например this_thread::sleep_for(chrono::milliseconds(1000));
То Task1 выполнился бы 2-3 раза, до того момента, пока поток 2 полностью не завершит работу.
//————————————————————————————————————
Примечание: в представленной программе происходит «параллельное» обращение к одним и тем же ресурсам – консоли, из-за чего могут возникать «ошибки», объясним это на картинке
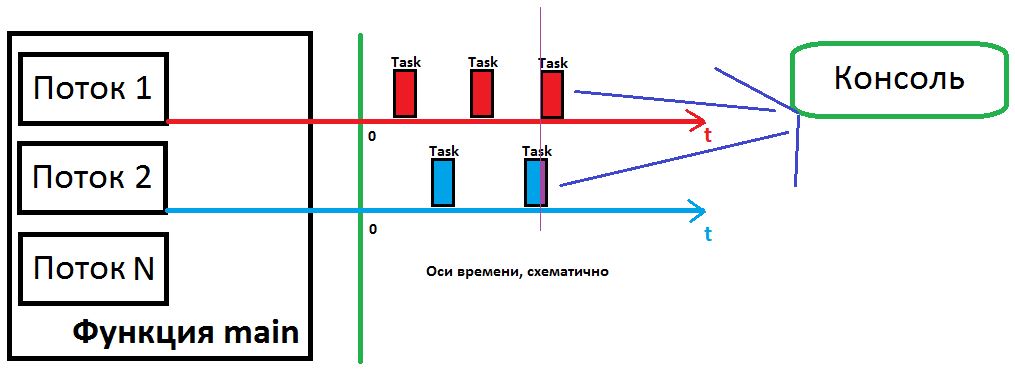
В момент, когда задача потока 2 не успела что-то передать в консоль задача из потока 1 передает свой данные в консоль, а как было рассказано ранее планировщик сохраняет текущее состояние задачи и возвращается к нему позднее, в результате может произойти так:
Задача 2: написала что-то в консоль (не до конца)
Задача 1: написала что-то в консоль
Задача 2: дописала конец
Тут стоит оговориться, что временные кванты могут иметь некоторый сдвиг, т.к. планировщику нужно забрать и записать некоторые переменные, из-за чего временные слоты могут немного смещаться, в результате рано или поздно задачи могут «совпасть» по времени и произойдет ситуация описанная выше.
Для борьбы с подобным используются механизмы ограничения доступа (мьютексы, семафоры и очереди.)